
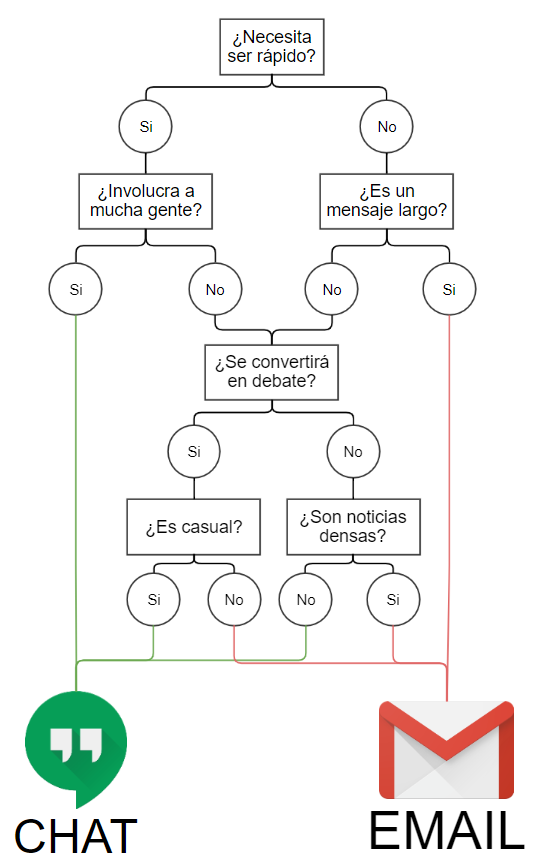
Buenas prácticas: ¿Email o chat?
Estás a punto de enviar un mensaje para actualizar a su compañera de trabajo sobre su último proyecto. ¿Escribes un correo electrónico o le escribes a Hangouts?
Tradicionalmente, los mejores casos para usar el correo electrónico son cuando:
- El contenido es demasiado largo para enviar mensajes.
- El mensaje es información pesada.
- El mensaje requiere formalidad.
- Es la primera vez que contactas a alguien
Los mejores casos para usar el chat son cuando:
- Debe ser rápido y oportuno
- El mensaje es conciso.
- Es un diálogo con múltiples personas
- La discusión debe ser más informal.
Árbol de decisión
Por qué
Oportunidad
El correo electrónico es asíncrono, lo que significa que un correo electrónico que envía a su compañero de trabajo no es en tiempo real como
lo es la mensajería. Esta es una diferencia clave para el razonamiento detrás del uso de uno versus el otro. La mensajería es instantánea, por lo
que sería más rápido que el correo electrónico cuando se trata de enviar información a alguien.
Según un estudio sobre el uso de mensajes por parte de IBM, la razón principal por la cual las personas eligen usar mensajes en cualquier otro
medio en un momento dado es porque permite una «respuesta rápida» y «respuestas rápidas y cortas».
Longitud
Originalmente, el chat estaba destinado a ser breve, mientras que el correo electrónico podía manejar mensajes más voluminosos y con mucho
contenido. Esto es una ventaja cuando se trata de mensajes porque significa que puedes ser más informal y rápido con lo que tienes que decir.
Pedir a los compañeros de trabajo que almuercen contigo se comunica mejor a través de mensajes, mientras que dar a alguien detalles largos
sobre un informe sería mejor por correo electrónico.
Diálogo
Tanto el correo electrónico como la mensajería se usan para el diálogo, pero el correo electrónico de ida y vuelta es muy diferente a la
mensajería. El chat es mejor si la conversación continuará durante más de unas pocas oraciones. El chat también refleja el cara a cara
más que el correo electrónico, lo que también es una razón para usar uno sobre el otro cuando se trata de largas conversaciones en línea.
Según un estudio de The Radicati Group, «el uso comercial de mensajería instantánea está creciendo a un ritmo mucho más rápido que el uso
de mensajería instantánea por parte de los consumidores». El estudio analiza todo tipo de mensajes, incluidos mensajes instantáneos,
mensajería instantánea pública, mensajería instantánea empresarial y mensajería móvil. El crecimiento de la mensajería muestra que el correo
electrónico no es la única forma de enviar un mensaje en el trabajo.
Problema resuelto!
Chuleta de YAML para Kubernetes en GCP
Nunca viene mal una chuleta cuando se trabaja con Kubernetes. En este caso, es una chuleta especial para el entono de GKE en la plataforma de GCP. En este caso, son el tipo de cargas de trabajo, servicios, etc. que más suelo usar en mi día a día. Espero que os sean de utilidad.
Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: name-deployment
namespace: dev
labels:
app: app-name
spec:
replicas: 1
selector:
matchLabels:
app: app-name
template:
metadata:
labels:
app: app-name
spec:
containers:
- name: container-name
image: container-image:tag
ports:
- containerPort: 1234
envFrom:
- configMapRef:
name: configmap-name
- secretRef:
name: secret-name
volumeMounts:
- name: name-vol
mountPath: /unix/source/route/map
volumes:
- name: name-vol
persistentVolumeClaim:
claimName: name-pvc
StatefulSet
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: name-statefulset
namespace: dev
labels:
app: app-name
spec:
serviceName: app-service-name"
replicas: 1
selector:
matchLabels:
app: app-name
template:
metadata:
labels:
app: app-name
spec:
containers:
- name: container-name
image: container-image:tag
ports:
- containerPort: 1234
name: port-name
resources:
limits:
memory: "2000Mi"
requests:
memory: "300Mi"
envFrom:
- configMapRef:
name: configmap-name
- secretRef:
name: secret-name
volumeMounts:
- name: name-vol
mountPath: /unix/source/route/map
volumes:
- name: name-vol
persistentVolumeClaim:
claimName: name-pvcCronjob
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: name-cronjob
namespace: dev
spec:
schedule: "01 0 * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: container-name
image: container-image:tag
args:
- /bin/sh
- -c
- sh /scripts/script.sh
restartPolicy: Never
PVC
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: name-pvc
namespace: dev
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 25Gi
ConfigMap
apiVersion: v1 kind: ConfigMap metadata: name: genportal-integration-config namespace: dev data: #Comments VAR_NAME: "value"
Secrets
apiVersion: v1 kind: Secret metadata: name: name-secret namespace: dev type: Opaque data: VAR_NAME: "password_in_base_64"
Service
apiVersion: v1
kind: Service
metadata:
name: name-service
labels:
app: app-name
namespace: dev
spec:
ports:
- port: 1234
protocol: TCP
targetPort: 1234
selector:
app: app-name
sessionAffinity: None
type: LoadBalancer / ClusterIP / NodePort
status:
loadBalancer: {}
Tipos de servicio en función de su comportamiento:
- ClusterIP: expone el servicio en una IP interna del clúster. Elegir este valor hace que el Servicio solo sea accesible desde dentro del clúster. Este es el ServiceType predeterminado.
- NodePort: expone el servicio en la IP de cada nodo en un puerto estático (el NodePort). Se crea automáticamente un servicio ClusterIP, al que se enruta el servicio NodePort. Podrá ponerse en contacto con el servicio NodePort, desde fuera del clúster, solicitando <NodeIP>: <NodePort>.
- LoadBalancer: expone el servicio de forma externa mediante el equilibrador de carga de un proveedor de nube. Los servicios NodePort y ClusterIP, a los que se enruta el equilibrador de carga externo, se crean automáticamente.
Problema resuelto!
Chuleta de PSQL
Aunque te hayas pegado a menudo con una base de datos postgresql, normalmente, se tocan de uvas a peras. Es difícil acordarse de todo, y por ello, hoy os dejo mi chuleta personal cuando no me acuerdo de algo.
Ficheros de configuración
/var/lib/postgresql/11/main' # use data in another directory
/etc/postgresql/11/main/postgresql.conf' #default conf file
/etc/postgresql/11/main/pg_hba.conf' # host-based authentication file
Conectarse desde cliente psql
Para hacer login en la BD postgres, utilizaremos la siguiente sintaxis:
psql -h [HOST] -U [user] [BD]Ejemplo:
psql -h localhost -U user_name db_name
Visualizar ROLES
\duResultado:
Lista de roles
Nombre de rol | Atributos | Miembro de
-----------------+------------------------------------------------+------------
postgres | Superusuario, Crear rol, Crear BD, Replicación | {}
xxxxxxxxx | Superusuario | {}
yyyyyyyyyyy | | {}Crear un GRUPO
CREATE ROLE nombre [ [ WITH ] opción [ ... ] ]Donde opción puede ser:
SUPERUSER | NOSUPERUSER
| CREATEDB | NOCREATEDB
| CREATEROLE | NOCREATEROLE
| CREATEUSER | NOCREATEUSER
| INHERIT | NOINHERIT
| LOGIN | NOLOGIN
| REPLICATION | NOREPLICATION
| CONNECTION LIMIT límite_conexiones
| [ ENCRYPTED | UNENCRYPTED ] PASSWORD 'contraseña'
| VALID UNTIL 'fecha_hora'
| IN ROLE nombre_de_rol [, ...]
| IN GROUP nombre_de_rol [, ...]
| ROLE nombre_de_rol [, ...]
| ADMIN nombre_de_rol [, ...]
| USER nombre_de_rol [, ...]
| SYSID uidEjemplo:
CREATE GROUP dev WITH LOGIN NOCREATEDB NOSUPERUSER NOCREATEROLE;Dar permisos de conexión sobre una BD
GRANT { { CREATE | CONNECT | TEMPORARY | TEMP } [,...] | ALL [ PRIVILEGES ] }
ON DATABASE database_name [, ...]
TO { [ GROUP ] role_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]Para más info de GRANT sobre postgres, visitar:
Postgres GRANT
Ejemplo:
GRANT CONNECT ON DATABASE tellmegen TO dev;Mostrar todos los SCHEMA disponibles
select schema_name from information_schema.schemata;
Resultado:
schema_name
--------------------
isisaudit
isiscommand
isissecurity
isissessionlogger
pg_toast
pg_temp_1
pg_toast_temp_1
pg_catalog
information_schema
publicDar permisos de SELECT, INSERT… sobre SCHEMA
GRANT { { SELECT | INSERT | UPDATE | DELETE | TRUNCATE | REFERENCES | TRIGGER }
[,...] | ALL [ PRIVILEGES ] }
ON { [ TABLE ] table_name [, ...]
| ALL TABLES IN SCHEMA schema_name [, ...] }
TO { [ GROUP ] role_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]Ejemplo:1
GRANT SELECT, INSERT, UPDATE, DELETE ON ALL TABLES IN SCHEMA public TO dev;Crear usuario y agregarlo a grupo
Utilizaremos la misma sintaxis que para crear un grupo. Ejemplo:
CREATE ROLE user_name WITH LOGIN NOCREATEDB NOSUPERUSER NOCREATEROLE CONNECTION LIMIT 1 PASSWORD 'password' IN GROUP dev;Es interesante establecer CONNECTION LIMIT 1, para evitar suplantación de identidad del usuario
Cambiar de grupo al usuario
Eliminar usuario del grupo:
REVOKE user_name FROM group_name;Modificar el fichero de conexión pg_hba.conf
Para permitir el acceso del usuario, hay que modificar el fichero pg_hba.conf. Esta configuración no funciona para usuarios, así que para permitir el acceso, habrá que añadir a cada usuario de manera individual.
/var/lib/pgsql/9.3/data/pg_hba.confo o para postgres11:
/etc/postgresql/11/main/pg_hba.confLa sintaxis del fichero debe de llevar alguna de las siguientes formas:
# local DATABASE USER METHOD [OPTIONS]
# host DATABASE USER ADDRESS METHOD [OPTIONS]
# hostssl DATABASE USER ADDRESS METHOD [OPTIONS]
# hostnossl DATABASE USER ADDRESS METHOD [OPTIONS]Ejemplo para login local:
local database_name user_name peerEjemplo para login remoto / pgadmin:
host database_name user_name ip/32 trustReiniciar siempre el servicio de postgres para aplicar cambios:
service postgresql-9.3.service restartProblema resuelto!
Snapshots periódicos de un PVC en GCP con Google SDK + Bash + CronJob
Pues ahí va la historia de este script:
Resulta que queremos mover una base de datos, la típica postgresql, de una maquina virtual a un pod de kubernetes. Hay muchos factores a tener en cuenta: Si se va a hacer subida de versión, como importar una copia de la base de datos, persistencia de discos… Aunque el que más me preocupaba era el disaster recovery.
Con una VM era sencillo. Script sacado de un blog de google y adaptado al entorno GCP, cambiando el almacenamiento local por un bucket de Storage. Pero claro, la mayoría de imágenes de postgresql vienen sobre alpine, que viene con las funcionalidades más que justas para que su consumo sea mínimo.
Se me ocurrieron un par de soluciones para abordar el problema:
- Instalar cron en el archivo Dockerfile de la imagen. Importar también los scripts actuales de la VM a dicha imágen. En definitiva, emular la VM en el entorno GKE.
- Levantar una imagen google/cloud-sdk, copiar un script .sh que trabajara con snapshots de Kubernetes y ejecutarlo desde un CronJob.
Al final, la que me pareció más adecuada fue la segunda. Y es que hace poco, intentando implementar ELK, descubrí «nuevos» tipos de carga de trabajo más allá de los deployments: Los CronJobs.
Un CronJob es un tipo de carga de trabajo que permite ejecutar trabajos en una programación basada en el tiempo. Estos trabajos automatizados se ejecutan como tareas Cron en un sistema Linux o UNIX.
Este tipo de carga de trabajo, junto a la potencia del SDK de Google, que permite trabajar con cuentas de servicio de permisos limitados, hacen posible que este script funcione. Eh aquí mis archivos «mágicos»:
Dockerfile
FROM google/cloud-sdk:latest
RUN mkdir /scripts
COPY ./[service-account-key].json /scripts
COPY ./snapshot_creation.sh /scripts
RUN chmod +x /scripts/snapshot_creation.sh
CMD tail -f /dev/nullPara poder utilizar GKE de forma desatendida, es necesario utilizar una cuenta de servicio. Os dejó aquí un enlace de como activar y empezar a usar una cuenta de servicio con GCP.
Script en Bash
#VAR definition
account_service_email="[account-service-email]"
account_service_json_dir="/scripts/.[service-account-key].json"
cluster_name="[cluster-name]"
cluster_zone="[cluster-zone]"
date=$(date +%Y%m%d-%H%M)
gcp_project_name="[gcp-project-name]"
pvc_name="pvc-[id]"
snapshot_name=$date-prod-psql-snapshot
snapshot_namespace="[kubernetes-namespace]"
#Create YAML
printf "apiVersion: snapshot.storage.k8s.io/v1beta1 \n" > snapshot.yaml
printf "kind: VolumeSnapshot \n" >> snapshot.yaml
printf "metadata: \n" >> snapshot.yaml
printf " name: $snapshot_name \n" >> snapshot.yaml
printf " namespace: $snapshot_namespace \n" >> snapshot.yaml
printf "spec: \n" >> snapshot.yaml
printf " source: \n" >> snapshot.yaml
printf " persistentVolumeClaimName: $pvc_name" >> snapshot.yaml
#Create snapshot
gcloud auth activate-service-account $account_service_email --key-file=$account_service_json_dir --project=$gcp_project_name
gcloud container clusters get-credentials $cluster_name --zone $cluster_zone --project $gcp_project_name
kubectl create -f snapshot.yaml --save-config
#Remove old versions
snapshot_count=`kubectl get volumesnapshot | grep prod-psql-snapshot | wc -l`
digest_array=(`kubectl get volumesnapshot | grep prod-psql-snapshot | awk '{print $1}'`)
if [ $snapshot_count -gt 14 ]
then
oldest_snapshot=`echo ${digest_array[0]}`
kubectl delete volumesnapshot $oldest_snapshot
fiLo que hago con este script es generar el YAML de un VolumeSnapshot, me autentico con la cuenta de servicio y creo ese snapshot. Para dejarlo todo limpio, cuento el número de copias al finalizar, y si pasan de 14, borro las últimas. Para más info acerca de como trabajar con los VolumeSnapshots en GCP, podéis consultarlo aquí.
CronJob
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: snapshot
spec:
schedule: "01 0 * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: backup
image: gcr.io/[project-name]/[image_name]
args:
- /bin/sh
- -c
- sh /scripts/snapshot_creation.sh
restartPolicy: NeverY ya estaría! Problema resuelto!
Pipeline en Jenkins para Rollback en Función del Entorno
La entrada de hoy es algo de lo que me siento realmente orgullosa. Llevo pocos meses trabajando con Jenkins y familiarizándome con su lenguaje, y hacer un script que te permita el rollback es una herramienta que pienso guardar en mi cajón de sastre.
Las necesidades que tenía eran:
- Elegir la imagen del container registry para un deployment y un container dado de Kubernetes, en función del entornos, en mi caso prod y dev.
- Necesitaba que me generara una lista de las etiquetas de la imagen del Container Registry de GCP en función del entorno.
- Necesitaba que fuera interactivo, y que el usuario que lo lanza pudiera decidir que versión restaurar.
En mi caso, he elegido el objeto de Jenkins pipeline, que me da un poco más de manga ancha para «programar». Y este es el resultado:
pipeline {
agent any
environment {
ENVIRONMENT = ""
IMAGE = gcr.io/[PROJECT_ID]/[IMAGE_NAME]
CMD=""
TAGS=""
K8_OBJ="deployment/[deployment-name]"
CONTAINER="[container_name]"
}
stages {
stage("Select Environment") {
steps {
script {
// Variables for input
// Get the environment
def envInput = input(
id: 'envInput', message: 'Enter path of test reports:?',
parameters: [
choice(name: 'ENVIRONMENT',
choices: ['prod','dev'].join('\n'),
description: 'Please select the Environment')
])
// Save to variables. Default to empty string if not found.
ENVIRONMENT = envInput?:''
}
}
}
stage("Select IMAGE f(x) env") {
steps {
script {
if (ENVIRONMENT == 'prod') {
//Image si prod
IMAGE = "gcr.io/[PROJECT_ID]/[IMAGE_NAME]"
} else {
//Image si dev
IMAGE = "gcr.io/[PROJECT_ID]/[IMAGE_NAME]"
}
}
}
}
stage("Select available tag") {
steps {
script {
//Generar la lista de etiquetas disponibles para la imagen dada
CMD="gcloud container images list-tags $IMAGE | awk 'NR==2,NR==12' | awk '{print \$2}' | awk -F, '{print \$1}'"
TAGS=sh (returnStdout: true, script: CMD ).trim()
//Recoger la etiqueta seleccionada por el usuario
def tagInput = input(
id: 'tagInput', message: 'Enter path of test reports:?',
parameters: [
choice(name: 'TAGS',
choices: [TAGS].join('\n'),
description: 'Please select the Environment')
])
//Guardar la etiqueta seleccionada por el usuario.
TAG = tagInput?:''
}
}
}
stage("Rollback To Selected Version"){
steps {
sh "kubectl set image ${K8_OBJ} ${CONTAINER}=${IMAGE}:${TAG} --record -n ${ENVIRONMENT}"
}
}
}
}Y ya estaría. Problema resuelto!
Script en bash para eliminar imágenes del Container Registry de GCP
Hoy una entrada sencilla pero efectiva. Al venir de sistemas, me cuesta más que a un desarrollador elaborar código. Y por eso es que me siento tan orgullosa de mis scripts.
En esta ocasión, utilizo la herramienta de comandos en linea de GCP, glcoud.
Para listar:
gcloud container images list-tags [HOSTNAME]/[PROJECT-ID]/[IMAGE_NAME]Para eliminar:
gcloud container images delete [HOSTNAME]/[PROJECT-ID]/[IMAGE_NAME]@sha256:DIGEST --quietEl script quedaría tal que así:
#!/bin/bash
declare -a digest_array
#Recoger todas imágenes del repositorio pasado en la llamada al script. Con awk recogemos solo la primera columna que corresponde con el DIGEST.
digest_array=(`gcloud container images list-tags "$1" | awk '{print $1}'`)
#En nuestro caso, queremos conservar las 3 imágenes más recientes. Por ello, el contador es 4 (columna del encabezado + 3 imágenes).
for i in "${digest_array[@]:4}"
do `gcloud container images delete "$1"@sha256:"$i" --quiet --force-delete-tags`
done
La llamada por terminal, sería:
./delete_old_images.sh "[HOSTNAME]/[PROJECT-ID]/[IMAGE_NAME]"Problema resuelto!
Mis claves para gestionar la mente cuando realizas tareas de helpdesk
Los helpdesk somos todas aquellas personas en la sombra, haciendo de parapeto entre los clientes finales y el equipo IT. Las funciones principales, bien sean helpdesk puros o sysadmin que asumimos esas funciones, es intentar solucionar lo más prontamente posible los problemas de clientes o compañeros.
Es un trabajo mal pagado -unos 18k brutos si tienes suerte-, con una alta carga de estrés, cuya importancia no se reconoce lo suficiente. Son la cara visible cuando el cliente tiene un problema, fundamentales para no sobrecargar la estructura y hacer que todos los mecanismos funcionen correctamente.
Los helpdesk son indiscutiblemente necesarios en cualquier entorno empresarial, tanto si la empresa tiene 10 empleados como si tiene 500. Un buen servicio de helpdesk ayuda a que los clientes no se sientan frustrados, agiliza y resuelve la problemática diaria, e incluso, según el entorno, aumenta la productividad.
Dicho todo esto, trabajar de helpdesk implica altos niveles de empatía, paciencia, flexibilidad, proactividad y mejora continua. Debemos tener en cuenta que debido a la pandemia ese trabajo se ha vuelto aún más complicado. Muchas trabajadoras optamos por la modalidad teletrabajo, que tiene sus ventajas y sus inconvenientes.
Uno de esos problemas que experimentamos es la comunicación. Y es que esta se ha tornado bastante difícil, porque ahora abusamos de herramientas de comunicación escrita, como el chat o el email. Esto da lugar a una serie de situaciones habituales que antes no lo eran, como:
- Información incompleta. Una coma, un signo de interrogación… Cambia el sentido completo de la frase, lo cual me lleva al siguiente punto.
- Necesidad de una definición minuciosa de las problemáticas. Siempre es importante, pero con teletrabajo, aún más. Una captura bien tomada puede ser diferencial para una resolución temprana.
- Malos entendidos. Ocurren por muchos factores, aunque lo que he acusado más sensiblemente es el salto generacional. La forma de escribir de un boomer y de un milenial, por lo general, da cambios bastante bruscos.
- Grado de sensibilidad alto. Los clientes se sienten indefensos, cuando se ven obligados a utilizar herramientas tipo helpdesk, o dependen de que su problemática se resuelva por email o chat. Su grado de confianza en la efectividad de estas herramientas les hace sentirse vulnerables.
Me encanta todo lo que tenga que ver con sistemas, desde un Jenkins, pasando por Kubernetes, monitorización, seguridad… Pero trabajar de sistemas, está muy ligado a las labores de helpdesk, en mayor o menor porcentaje de tiempo. Y por desgracia se me da mejor comunicarme con las máquinas que con los seres humanos.
Al final, trabajar con personas es lo más difícil. A veces tenemos días buenos, y otros, no lo son tanto. A veces explicar las cosas es difícil, las cosas no salen como esperabas, o te puedes tomar las afrentas como algo personal, cuando no lo son. Y a pesar de todo esto, tienes que tener temple y sangre fría y nunca perder la sonrisa ni las buenas maneras
Mis Claves Para Afrontarlo
1. Respeto
Un aspecto fundamental que tiene que estar presente en los dos sentidos. Tanto del cliente hacia ti, como de ti hacia el cliente.
El helpdesk no deberá jamás faltar al respeto, ni gritar, ni insultar, ni dejar en ridículo… Pero lo mismo se le supone a la parte cliente.
En caso de que esta premisa no se cumpla, lo primero sería tratarlo con el cliente de la manera mas educada posible. En caso de persistencia, se debería tratar con el supervisor o responsable correspondiente, para tomar las medidas que sean oportunas.
Por supuesto, si un usuario entra de malas maneras, nunca, repito nunca, se le tiene que devolver con la misma manera. Si te grita, no le grites. Si te dirige una queja que escapa a tu paraguas de responsabilidad, le rediriges a la persona que puede solventarlo.
Respeto, respeto y más respeto.
Tenemos que hacer focus en que nuestra labor es ayudar, e intentar concentrarnos en el apartado técnico. Dejar de lado el aspecto emocional, los adjetivos peyorativos, las frases de desdén… Es un poco frío, pero al final es lo que es: un trabajo.
Empatía
Es una de las cosas más difíciles de cualquier trabajo de atención al cliente: Ponerse en el lugar del otro. Cómo piensa, como actúa, porque se comunica de la manera que lo hace…
Es un clásico las incidencias «urgentes». Para un cliente, las prioridades son muy distintas a las de alguien de sistemas. El cliente siempre va a querer ser el primero, intentar que se lo soluciones para ayer.
Algunas de mis frases de bolsillo que siempre me funcionan son:
- Estoy con una incidencia super urgente. Pero tan pronto como lo solucione, eres el primero en ser atendido.
- Ahora mismo me pillas acabando [TAREA]. Dame 10 minutos que lo cierre y me pongo enseguida.
- Avísame cuando tengas un momento y lo revisamos junt@s.
A veces es un poco frustrante, pero la interrupción y el separarse del contexto es algo normal y natural en sistemas y helpdesk. Por experiencia propia, es preferible atender el telefono y decir «no puedo ahora» a dejarlo sonar.
Es importante, que aunque la atención no pueda ser inmediata, la persona reciba un feedback de que su petición ha sido tramitada correctamente y que se le atenderá a la mayor brevedad posible. Eso hará que el resto del proceso sea más ágil y más agradable por ambas partes.
Por supuesto, ser conscientes de que si alguien reclama la ayuda de un helpdesk, no lo hace por gusto, sino que no le queda más remedio. Eso puede ocasionar en algunas personas sentimiento de debilidad y vulnerabilidad. Es por eso que hay que ser especialmente amables, comprensivos, empáticos y siempre medir nuestras palabras.
Protocolo
Realizar labores de helpdesk es mucho más fácil cuando hay protocolos definidos. Qué hacer cuando hay que dar un alta nueva, o cómo funciona el flujo de compras. Si se sale del protocolo, es muy fácil indicar cual es el cauce a seguir.
En caso de que no haya protocolo, tenemos que ser flexibles.
A veces pasa. Las empresas son jóvenes y no los han definido, o no tan jóvenes pero no se ha visto necesidad de controlar ciertos aspectos. Tenemos que tener en cuenta también que cada caso es diferente. A veces se soluciona con preguntar al responsable, en otras ocasiones hay que parar la incidencia y a veces hay que actuar sin analizar mucho los riesgos.
En cualquier situación, la mejor opción es siempre mantener al usuario informado. Y en caso de que sea necesario, definir nuevas metodologías y acciones a ejecutar.
Herramientas para el control y la gestión de incidencias
No se puede realizar labores de helpdesk sin un software adecuado. Da igual como se llame la herramienta: Remedy, ManageEngine, SpiceWorks, Jira…
Con este tipo de software podemos definir:
- Tiempos empleados en las incidencias.
- Asignación por técnico. Es útil repartir la carga entre los miembros del equipo.
- Registro de las actuaciones llevadas a cabo. Tanto para nosotros mismos, como para otros compañeros si nos toman el relevo.
- Categoría y subcategoría. Muy útil si se quieren localizar los ladrones de tiempo
- Definición de tiempos de respuesta y de resolución.
- Establecer prioridades
Canales
Esto va muy ligado al tema de protocolos y a las herramientas de helpdesk. Hay muchas formas de recibir las incidencias, pero es necesario concienciar a la organización de la necesidad de unificar los canales para ofrecer un mejor servicio.
Lo recomendado siempre es recibir las peticiones por la misma vía, de la misma manera, y a veces que desde el mismo interlocutor. Pero seamos sinceros: no es lo habitual. Por eso, hay que ser flexibles e indicar como es la manera correcta de proceder para próximas ocasiones.
El tener unos canales establecidos y trabajar siempre de la misma manera, nos ayuda a ser más ágiles y prestar mejor servicio.
Prioridades
Cuando todo es urgente, nada es urgente.
Anónimo
Si bien ITIL nos ayuda con el tema de prioridades, en función del impacto en la organización, numero de usuarios afectados, urgencia de la petición… Es algo bastante teórico. Hay muchos factores que influyen, como el apellido y el cargo, los plazos, la duración de cada incidencia, si esta ha sido previamente resuelta o no, si requiere investigación…
Al final, son todos estos factores los que ha de definirnos la prioridad a asignar a cada caso. Pero una vez definidas las prioridades, siempre en la medida de lo posible, hay que intentar respetarlas.
No agobiarse – Buena organización
A veces es necesario parar. Vamos a 100 por hora, y a veces algo sencillo se nos hace una montaña.
En mi caso, suelo utilizar técnicas de yoga, como el pranayama, para controlar la respiración. Eso junto a una buena organización, hace que hagamos más por menos.
Y si necesitas un descanso, descansa. Sal a la calle, da una vuelta, ve a tomar un café… El mecanismo que prefieras. Trabajar con estrés de más no va a ayudar a que las cosas salgan antes ni mejor.
No es personal
Si recibes ataques, sea cual sea la incidencia a la que te enfrentes, no va contra tu persona.
En mi caso me cuesta separar el ámbito personal y el profesional. Me encanta mi trabajo, así que es mi trabajo y mi hobby. Pero si con los años he aprendido algo, es que, pase lo que pase, no es contra ti. Por supuesto, dejar de lado las disputas o tensiones que pueden surgir con los clientes. No aportan valor y entorpecen nuestras funciones.
Volvemos al punto de la empatía. Quizás la persona ha tenido un mal día, o está nerviosa, o necesita algún punto de fuga. Es común que se pague con el eslabón más débil de la cadena. Pero a pesar de todo esto, si estás convencido de que has hecho tu trabajo lo mejor posible, hay que repetirse: Esto no es personal.
Base de datos de conocimiento
Poco a poco el trabajo en oficina va evolucionando. Y es el mismo usuario el que te pide la manera de hacer las cosas. Os aseguro que lo último que quiere un usuario a la hora de renovar su contraseña, es tener que pasar por el departamento IT para hacer ese cambio. Por otra parte, muchas veces las cosas se «hacen mal» porque no se saben hacer de otra manera.
Una base de datos de problemas habituales, un buen FAQ, y todo este tipo de herramientas con las que se trasmite la información, ayuda a un mejor funcionamiento, agiliza el servicio y reduce el tiempo de inactividad.
Pero ojo, todo sin abusar. Me gusta mucho utilizar ciertas frases cuando envío documentación de una solución a clientes:
- Si a pesar de la documentación tienes dudas, quedo a tu disposición.
- Si esto que te adjunto no lo resuelve, lo vemos en detalle tan pronto pueda.
- Si esto no funciona, tendremos que remitir el caso al soporte del producto.
Pero como siempre, equilibrio. Ni todo manuales ni todo conexiones remotas.
Aprender de las críticas y comentarios
Siempre seguir aprendiendo.
Toda la información que nos puedan trasmitir clientes y usuarios es altamente valiosa. Para automatizar, para mejorar, para hacer las cosas de una manera diferente… Tengámoslo siempre en cuenta.
Estos puntos están basados en mi experiencia. Y como todos somos diferentes, habrán cosas que nos funcionen y otras que no.
¿Qué técnicas usáis vosotros para gestionar vuestra cabeza cuando tenéis que hacer helpdesk?
Configurar SnipeIT como deployment en Kubernetes sobre Google Cloud Platform
La nota mental de hoy va sobre una herramienta OpenSource para la gestión de inventario que estamos probando en la oficina: SnipeIT. La manera de documentar como realizar una instalación, ya fuera sobre VM o sobre docker me pareció realmente confusa.
Invertí bastantes horas en entender los ficheros de configuración. Cosas tan sencillas como especificar que el docker-compose up debía ir con el atributo -d, para poder seguir utilizando la consola, no estaban especificadas. Al igual que el orden para realizar los pasos.
A continuación, os detallo los pasos que seguí para poder llevar a cabo el despligue como deployment en el entorno de Kubernetes de GCP.
Introducción
Snipe-IT permite una gestión fácil para 4 tipos principales de activos:
- Equipos/Terminales
- Licencias
- Accesorios
- Consumibles
Permite tener una traza de quién tiene qué portátil/pc, cuándo se ha comprado, dónde, qué licencias de software y accesorios están disponibles, etc.
Es un software con solamente interfaz web, y alguna de las cosas que más me han gustado es la capacidad de vincular los usuarios con un LDAP o AD. Está basado en el framework Laravel, y el fichero de configuración es el estándar del mismo.
Snipe-IT requiere de una conexión a base de datos para almacenar el contenido. Es compatible con varios tipos diferentes de bases de datos, pero en esta nota mental, trabajaremos con MySQL 5.6
Ojo: Para poder lanzar correctamente la aplicación en Kubernetes es necesario generar una key.
Instalación en local
En la documentación de SnipeIT no hay un apartado para Kubernetes, así que lo que tuve que hacer es adaptar los archivos que ellos facilitaban.
Estos son los archivos para poder lanzar snipe-it como contenedor local.
docker-compose.yml
version: '3'
services:
snipe-mysql:
container_name: snipe-mysql
image: mysql:5.6
env_file:
- ./.env
volumes:
- snipesql-vol:/var/lib/mysql
command: --default-authentication-plugin=mysql_native_password
expose:
- "3306"
snipe-it:
image: snipe/snipe-it
env_file:
- ./.env
ports:
- "80:80"
depends_on:
- snipe-mysql
volumes:
snipesql-vol:SnipeIT corre un Apache de manera interna. En este caso he mapeado el 80 de la aplicación al 80 de mi máquina, para simplificarlo todo.
Por otra parte, este es el fichero de variables de entorno oficial:
.env
# Mysql Parameters
MYSQL_PORT_3306_TCP_ADDR=snipe-mysql
MYSQL_ROOT_PASSWORD=YOUR_SUPER_SECRET_PASSWORD
MYSQL_DATABASE=snipeit
MYSQL_USER=snipeit
MYSQL_PASSWORD=YOUR_snipeit_USER_PASSWORD
# Email Parameters
# - the hostname/IP address of your mailserver
MAIL_PORT_587_TCP_ADDR=smtp.whatever.com
#the port for the mailserver (probably 587, could be another)
MAIL_PORT_587_TCP_PORT=587
# the default from address, and from name for emails
[email protected]
MAIL_ENV_FROM_NAME=Your Full Email Name
# - pick 'tls' for SMTP-over-SSL, 'tcp' for unencrypted
MAIL_ENV_ENCRYPTION=tcp
# SMTP username and password
MAIL_ENV_USERNAME=your_email_username
MAIL_ENV_PASSWORD=your_email_password
# Snipe-IT Settings
APP_ENV=production
APP_DEBUG=false
APP_KEY=<<Fill in Later!>>
APP_URL=http://127.0.0.1:80
APP_TIMEZONE=US/Pacific
APP_LOCALE=enPara lanzarlo en local, situaremos nuestra consola en la carpeta donde hayamos generado estos dos archivos anteriores. A continuación, ejecutaremos el siguiente comando:
docker-compose up -dEl -d lo hará correr en segundo plano y podremos seguir trabajando con el mismo terminal
Generar la APP_KEY
Tenemos que acceder al bash del contenedor de snipe-it, para ello:
docker exec -it nombre-del-contenedor-snipe-it shY ejecutamos el siguiente comando:
php artisan key:generateNos debería devolver un texto tal que:
**************************************
* Application In Production! *
**************************************
Do you really wish to run this command? (yes/no) [no]:Escribimos yes y pulsamos Enter. Debería devolver algo similar a:
Application key [base64:mW05bo4UXv6D/t3ldTzjUvIbUkwyKdrPSVlr/mrE3Ac=] set successfully.La key en este caso sería:
base64:mW05bo4UXv6D/t3ldTzjUvIbUkwyKdrPSVlr/mrE3Ac=Es importante no olvidar el base64, puesto que sino, la aplicación no funcionará correctamente.
Archivos de configuración en Kubernetes
Necesitamos:
- Disco de almacenamiento persistente (PVC)
- Configmap para guardar las variables de sistema
- Secrets para guardar las variables sensibles y contraseñas
- Servicios, uno para mysql y otro para snipe-it.
- Deployment
01-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: snipeit-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi02-config.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: snipe-it-config
data:
# Mysql Parameters
MYSQL_PORT_3306_TCP_ADDR: "mysql-service"
MYSQL_PORT_3306_TCP_PORT: "3306"
MYSQL_DATABASE: "snipeit"
MYSQL_USER: "snipeit"
# Email Parameters
# - the hostname/IP address of your mailserver
MAIL_PORT_587_TCP_ADDR: smtp.whatever.com
#the port for the mailserver (probably 587, could be another)
MAIL_PORT_587_TCP_PORT: 587
# the default from address, and from name for emails
MAIL_ENV_FROM_ADDR: [email protected]
MAIL_ENV_FROM_NAME: Your Full Email Name
# - pick 'tls' for SMTP-over-SSL, 'tcp' for unencrypted
MAIL_ENV_ENCRYPTION: tcp
# SMTP username and password
MAIL_ENV_USERNAME: your_email_username
MAIL_ENV_PASSWORD: your_email_password
# Snipe-IT Settings
APP_ENV: "production"
APP_DEBUG: "false"
APP_KEY: "base64:mW05bo4UXv6D/t3ldTzjUvIbUkwyKdrPSVlr/mrE3Ac="
APP_URL: "http://0.0.0.0:80"
APP_TIMEZONE: "Europe/Madrid"
APP_LOCALE: "es-ES"Dónde:
- MYSQL_PORT_3306_TCP_ADDR: «mysql-service» corresponde al servicio de de MySQL que crearemos en archivos posteriores.
- MYSQL_PORT_3306_TCP_PORT: «3306» es el valor por defecto del puerto de MySQL
- MYSQL_DATABASE: «snipeit» es el nombre por defecto de la base de datos
- MYSQL_USER: «snipeit» es el usuario por defecto de la base de datos.
- APP_KEY: Es la clave que hemos generado previamente en local.
03-secrets.yaml
apiVersion: v1
kind: Secret
metadata:
name: snipe-it-secret
type: Opaque
data:
MYSQL_ROOT_PASSWORD: "tu-contraseña-root-mysql-en-base-64"
MYSQL_PASSWORD: "tu-contraseña-root-mysql-en-base-64"04-mysql-service.yaml
apiVersion: v1
kind: Service
metadata:
name: mysql-service
labels:
app: snipeit
spec:
ports:
- port: 3306
protocol: TCP
targetPort: 3306
selector:
app: snipeit
sessionAffinity: None
type: LoadBalancer
status:
loadBalancer: {}En cuanto hablamos de servicios, no hay que perder de vista las etiquetas. Son las que nos permitirán asociar pods y deployments a servicios. En mi caso utilizo la etiqueta «app» para realizar posteriormente la concordancia en el deployment.
En mi caso he elegido desplegar tanto el servicio de MySQL como el de Snipe-IT como balanceador de carga, lo cual me generará una IP pública accesible. Podría hacerse también usando IP de Clúster y un Ingress, entre otras opciones.
05-snipeit-service
apiVersion: v1
kind: Service
metadata:
name: snipeit-service
labels:
app: snipeit
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: snipeit
sessionAffinity: None
type: LoadBalancer
status:
loadBalancer: {}06-deployment.yaml
apiVersion: "apps/v1"
kind: "Deployment"
metadata:
name: "snipeit-deployment"
labels:
app: "snipeit"
spec:
replicas: 1
selector:
matchLabels:
app: snipeit
template:
metadata:
labels:
app: snipeit
spec:
containers:
### mysql image ###
- name: snipe-mysql
image: mysql:5.6
ports:
- containerPort: 3306
envFrom:
- configMapRef:
name: snipe-it-config
- secretRef:
name: snipe-it-secret
volumeMounts:
- name: snipeit-vol
mountPath: /var/lib/mysql
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "sleep 60"]
### snipe it image ###
- name: snipeit
image: snipe/snipe-it
envFrom:
- configMapRef:
name: snipe-it-config
- secretRef:
name: snipe-it-secret
ports:
- containerPort: 80
volumeMounts:
- name: snipeit-vol
mountPath: /var/lib/snipeit
#volumes of the pod
volumes:
- name: snipeit-vol
persistentVolumeClaim:
claimName: snipeit-pvcDónde:
- snipe-it-config: Es el nombre asignado al fichero de ConfigMap
- snipe-it-secret: Es el nombre asignado al fichero de Secrets.
- snipeit-pvc: Es el nombre asignado al disco persistente creado.
- snipeit-vol: Es el nombre asignado al volumen para utilizar el pvc dentro de la plantilla del depliegue.
Recuerda: Has de tener previamente instalada la herramienta Google SDK y el plugin kubectl.
Para finalizar, desde la consola de SDK, nos situamos en la carpeta donde hayamos generado los ficheros de configuración y lanzamos.
kubectl create -f . --save-configNo te olvides de probar que todo funciona como se espera. En este caso, bastaría con poner en un navegador la IP pública que haya asignado Google para el balanceador de carga.
Os dejo la documentación oficial en la que me he basado, por si os es de utilidad.
Problema resuelto!
Synology C2 y sus diferentes opciones de backup
No se trata de una nota mental patrocinada (¡ojala!). Va destinada a todos aquellos que por suerte o por desgracia cuentan con una NAS Synology en su infraestructura.
El objetivo es desglosar los principales problemas que te puedes encontrar cuando usas este tipo de producto, ventajas y desventajas que ofrece la solución C2 frente a estos errores, los requerimientos para poder empezar, y por último, las opciones de la copia y sus diferencias.
Introducción
Synology se ha sabido adaptar bien al mercado, y ofrece bastantes opciones para hacer la copia en cloud: Azure, Google Drive, AWS… Esto está muy bien porque si ya trabajas con alguno de estos proveedores de nube, en pocos pasos, es bastante sencillo integrarlo.
Ahora bien, no nos engañemos. Lo que esperas de una copia de seguridad de una NAS es no tener que revisar que funcione, que la copia sea íntegra, fácil de restaurar, que puedas tener varios puntos de recuperación, y ya puestos a hacer la carta a los reyes magos, que en caso de necesitarlo tengas un soporte que te pueda echar un cable en el momento lo necesites.
Synology C2 es una solución cloud nativa diseñada para integrarse con las NAS de la misma marca.
Problemas habituales
- El tamaño de la NAS crece y crece, y te quedas sin espacio de almacenamiento en el Cloud.
- Falta de discriminación. Las copias a soluciones cloud suelen volcar el contenido sin filtrar si los archivos o carpetas han cambiado de nombre, lo que duplica contenido.
- Puntos de recuperación. Las copias a servicios cloud suelen carecer de esta funcionalidad, y es muy útil. Todos nos hemos tropezado con usuarios que querían la versión de hace una semana.
- Errores al restaurar. Podría ser el título de una película de terror. Tienes tu copia, y cuando vas a restaurar ¡Boom! Error desconocido.
Ventajas de Synology C2
- Herramienta nativa. Va a tener una integración mayor que el resto de las soluciones. Suele facilitar el soporte, al ser ambos Synology.
- Diferentes políticas de retención, personalizables.
- Múltiples puntos de restauración, en función de la política.
- Opción más económica, si lo comparamos con plataformas como GCP o Azure.
Desventajas
- La primera copia suele tardar varios días en hacerse. Recomiendo siempre previsión, antelación y planificación antes de hacer esta primera copia.
Rotación de copia
Es posible configurar C2 para que realice una rotación de las copias. Se trata de copias tipo GFS, lo que las convierte en una opción muy interesante. Este tipo de sistema no es nuevo, sin ir muy lejos, lo lleva usando Veeam Backup hace años. Es muy potente y nos ayuda a retener muchos datos al mismo tiempo nos da un alto nivel de compresión.
¡Ojo! Activar la rotación de copia hará que las copias de seguridad se eliminen automáticamente según la configuración de rotación.
Pero seamos realistas: Nadie va a querer restaurar un archivo eliminado de hace más de x meses. Esto nos ayudará con el problema archivos obsoletos nos consuman espacio de la copia. Además, que es posible evitar este comportamiento si se bloquean versiones desde el explorador de Información.
Requerimientos
- Synology NAS.
- DSM 6.0 o una versión posterior.
- Hyper Backup 2.1.2 o superior. Va a ser la herramienta con la que vas a gestionar la creación y la restauración de las copias.
- Cuenta de Synology.
Opciones de rotación de copia
A partir de versiones anteriores
Creará los puntos de restauración que le indiques en el apartado «Número máximo de versiones». Por defecto, te pondrá el valor 256 que equivale a 9 meses.
Synology te ofrece dos maneras de crear los puntos de restauración:

La opción «M» creará un punto diario con una sola versión por punto.

La opción «Y» creará un punto semanal, con 7 versiones en cada punto.
El resultado es el mismo, tienes una copia diaria de tus datos, así que la opción que elijas tiene que ser en función de tus necesidades.
Smart Recycle
Para mi, sin duda, la opción más cómoda. La política de retención es:
- Versiones cada hora desde las últimas 24h
- Versiones diarias desde hace 1 día hasta hace 1 mes.
- Versiones semanales con más de 1 mes.
Es cómodo, funcional y suele adecuarse a casi cualquier tipo de retención que necesite un contenido almacenado en NAS.
Retención personalizada
Si las opciones por defecto no se ajustan, puedes crear una retención personalizada.
Instalar Spark 2.3.2 + Scala 2.11 sobre Debian 10
En la nota mental de hoy voy a indicar cómo desplegar dos aplicaciones, las cuales nos van a facilitar mucho trabajar con BigData y lago de datos como Hadoop, con versiones en desuso (deprecated) pero que funcionan con JDK8.
Para está instalación nos hace falta tener instalado previamente JDK8. Puedes consultar como hacerlo para Debian 10 aquí.
Introducción
¿Qué es Spark?
Apache Spark es un framework de programación para procesamiento de datos distribuidos diseñado para ser rápido y de propósito general. Cuenta con flexibilidad e interconexión con otros módulos de Apache como Hadoop, Hive o Kafka.
En nuestro caso, lo vamos a utilizar para poder hacer uso de Scala.
¿Qué es Scala?
Es un lenguaje de programación orientado a objetos, bastante popular e integrable con herramientas como IntelliJ, Eclipse, . Una de sus mayores ventajas es la escalabilidad. Comúnmente, se dice que scala suple las carencias de Java, con lo que su uso y adopción está en auge.
El objetivo de esta nota mental no es entrar en detalle de scala, así que si tenéis curiosidad, os dejo un par de entradas interesantes:
Despliegue
Aunque se trata de una versión obsoleta, me parece interesante exponer el proceso que he seguido y me ha funcionado. Y es que a la hora de la verdad, cuando te tropiezas con el mundo real y las infraestructuras de muchas empresas «normales», prima la economía de la empresa. El resultado es que muchos de los sistemas no soportan últimas versiones.
Previo a todo esto, buenas prácticas, update y upgrade:
sudo apt-get update
sudo apt-get upgradeEste es el repositorio del cual voy a obtener los datos para la instalación:
https://github.com/apache/spark/archive/v2.3.2.zip
Lo primero es descargar spark, descomprimirlo y eliminar los ficheros descargados, dentro de la máquina donde vayamos a realizar la instalación.
sudo wget https://github.com/apache/spark/archive/v2.3.2.zip
sudo unzip v2.3.2.zip
sudo rm -rf v2.3.2.zipEn mi caso, voy a crearle una carpeta específica para la instalación, y voy a mover los archivos descomprimidos dentro de ella.
sudo mkdir /opt/spark
sudo mv spark-2.3.2/* /opt/spark Entramos en la carpeta que acabamos de crear y lanzamos los comandos de configuración para instalar scala. Para ello utilizaremos Maven (mvn) y Hadoop.
cd /opt/spark/
sudo ./dev/change-scala-version.sh 2.11
sudo ./build/mvn -Pyarn -Phadoop-2.6 -Dscala-2.11 -DskipTests clean packagePara verificar la instalación, podemos lanzar:
./bin/run-example SparkPi 10El siguiente paso quitar la extensión .template del script de configuración.
sudo mv conf/spark-env.sh.template conf/spar-env.sh
sudo nano conf/spark-env.shTenemos que buscar una linea similar a SPARK_LOCAL_IP , que suele ir comentada con #. Le asignaremos el siguiente valor:
SPARK_LOCAL_IP=127.0.0.1Por último, para utilizar scala, lanzaremos el siguiente comando:
./bin/spark-shell — master local[2]Problema resuelto!