
Alertas Útiles en Google Cloud Platform
Intro
Me gustaría empezar esta entrada con un síntoma que he sufrido bastante en las empresas donde he tenido el placer de trabajar:
El Día a Día Me Come (DDMC)
Fransu Rondán
Se podría aplicar en muchos aspectos, tanto personales como profesionales. Pero hoy me gustaría hacer hincapié en esa gran aliada, apenas utilizada en las infraestructuras de sistemas: La monitorización.
Da igual como se llame la herramienta: Stackdriver, Zabbix, Nagios… Es una inversión de tiempo que se recupera a corto plazo. Lo importante es tenerla, configurarla y hacerle caso.
Ventajas
- Detección e identificación temprana de problemas.
- Ejecución de acciones preventivas.
- Alertas y notificación de las incidencias.
- Generación de informes de rendimiento y seguridad.
- Capacidad para optimizar recursos.
¿Qué monitorizar?
En esta entrada no vamos a centrar en los indicadores del rendimiento (KPI) de VM y de contenedores de Kubernetes, en concreto la RAM y CPU, puesto que Google Cloud Platform es una plataforma demasiado flexible para detallarlo todo.
Memoria
Instancias de máquina virtual
| Nombre del recurso | VM Instance |
| Etiqueta del recurso en la consulta | gce_instance |
| Nombre de la métrica: | Memory utilization |
| Descripción de la métrica: | Tamaño en bytes de memoria usada obtenida utilizando el agente de stackdriver. |
| Etiqueta de la métrica en la consulta: | agent.googleapis.com/memory/percent_used |
| Tipos de memoria disponibles para la monitorización: | buffered cached free slab1 used |
| Nombre del recurso | VM Instance |
| Etiqueta del recurso en la consulta | gce_instance |
| Nombre de la métrica: | VM Memory Used |
| Descripción de la métrica: | Memoria actual usada en la VM. Solo disponible para las VM de la familia e2. |
| Etiqueta de la métrica en la consulta: | compute.googleapis.com/instance/memory/balloon/ram_used |
| Tipos de memoria disponibles para la monitorización: | buffered cached free slab1 used |
Kubernetes
| Nombre del recurso | GKE Container |
| Etiqueta del recurso en la consulta | k8s_container |
| Nombre de la métrica: | Memory Usage |
| Descripción de la métrica: | Uso de memoria en bytes |
| Etiqueta de la métrica en la consulta: | kubernetes.io/container/memory/used_bytes |
| Tipos de memoria disponibles para la monitorización: | evitable: Fácilmente reclamada por el kernel non-evitable: No fácilmente reclamada por el kernel |
CPU
INSTANCIAS DE MÁQUINA VIRTUAL
| Nombre del recurso | VM Instance |
| Etiqueta del recurso en la consulta | gce_instance |
| Nombre de la métrica: | CPU utilization |
| Descripción de la métrica: | Porcentaje de CPU usado obtenido utilizando el agente de stackdriver. |
| Etiqueta de la métrica en la consulta: | agent.googleapis.com/cpu/utilization |
| Estados de CPU disponibles para la monitorización: | idle: Cuando no lo está usando ningún programa. interrupt: Señales enviadas por dispositivos externos a la CPU para detener las actividades actuales. nice: Tiempo dedicado a ejecutar procesos con buen valor positivo. softirq: Cuando se ejecuta un controlador de interrupciones o una función diferible. steal: Tiempo que una CPU virtual espera una CPU real mientras el hipervisor está dando servicio a otro procesador. system: CPU utilizada por el sistema user: CPU utilizada por el usuario wait: cantidad de tiempo que una tarea tiene que esperar para acceder a los recursos de la CPU |
Hay muchos tipos de memoria, y todos deberían ser monitorizados. Sin embargo, considero que lo más fácil sería monitorizar que siempre tengamos un porcentaje libre de idle. No sabremos que tipo de memoria exactamente está dando el problema, pero detectaremos que algo está ocurriendo y podremos tomar medidas.
Podríamos configurar alertas, por ejemplo, que detectaran cuando la memoria idle disponible es inferior al 30% durante 1h.
| Nombre del recurso | VM Instance |
| Etiqueta del recurso en la consulta | gce_instance |
| Nombre de la métrica: | CPU utilization |
| Descripción de la métrica: | Utilización fraccionada de la CPU asignada. Los valores son típicamente números entre 0.0 y 1.0. Los gráficos muestran los valores como un porcentaje entre 0% y 100% |
| Etiqueta de la métrica en la consulta: | compute.googleapis.com/instance/cpu/utilization |
| Valores de CPU disponibles para la monitorización: | cpu/utilization |
Kubernetes
Debido a la forma de funcionar y a la lógica de Kubernetes, GCP no nos proporciona para los contenedores un parámetro utilization como pasaba con las máquinas virtuales. En su lugar nos ofrece los siguientes parámetros:
- kubernetes.io/container/cpu/core_usage_time
- kubernetes.io/container/cpu/limit_cores
- kubernetes.io/container/cpu/limit_utilization
- kubernetes.io/container/cpu/request_cores
- kubernetes.io/container/cpu/request_utilization
Sin embargo, si queremos saber el uso de CPU, los clusters de GKE al final son maquinas virtuales en el entorno de GCE. Para evitarnos sustos, siempre es recomendable tener el cluster monitorizado como una máquina más.
Discos / Volumenes
Instancias de máquina virtual
| Nombre del recurso | VM Instance |
| Etiqueta del recurso en la consulta | gce_instance |
| Nombre de la métrica: | Disk usage |
| Descripción de la métrica: | Disco usado en bytes obtenido utilizando el agente de stackdriver. Solo para VM Linux. |
| Etiqueta de la métrica en la consulta: | agent.googleapis.com/disk/bytes_used |
| Tipo de uso: | free reserved used |
| Nombre del recurso | VM Instance |
| Etiqueta del recurso en la consulta | gce_instance |
| Nombre de la métrica: | Disk usage in Bytes |
| Descripción de la métrica: | Disco usado en bytes. |
| Etiqueta de la métrica en la consulta: | compute.googleapis.com/guest/disk/bytes_used |
| Valores de CPU disponibles para la monitorización: | cpu/utilization |
Filtros:
- resource.namespace_name
- resource.container_name
- metric.memory_type:
- Values:
evictable: It is memory that can be easily reclaimed by the kernelnon-evictable. , Is memory that can not be easily reclamied by the kernel.
- Values:
Buenas prácticas: ¿Almacenaje cloud o NAS?
Estás a punto de guardar un documento pero no estás seguro donde debería estar guardado. ¿Lo guardas en el cloud o lo guardas en la NAS?
Tanto Cloud (OneDrive, Google Cloud) como la NAS son dos servicios de almacenamiento de archivos. Ambos son medios son complementarios entre sí dentro del lugar de trabajo, pero hay ciertos casos en los que es mejor usar uno u otro. Depende de la situación.
Tradicionalmente, los mejores casos para usar Cloud son cuando:
- Necesitas compartir un archivo/carpeta con externos a la organización.
- Es un archivo “vivo”. Se edita y modifica con frecuencia.
- Necesitas realizar trabajo colaborativo simultáneo sobre el archivo con otro compañer@.
- Es un archivo que solo lo vas a usar tu.
Los mejores casos para usar la NAS son cuando:
- No necesitas trabajo colaborativo
- Es un archivo “estático”, que sufre pocos o ningún cambio a lo largo del tiempo.
- Tiene que estar en un repositorio común para todos los miembros del equipo.
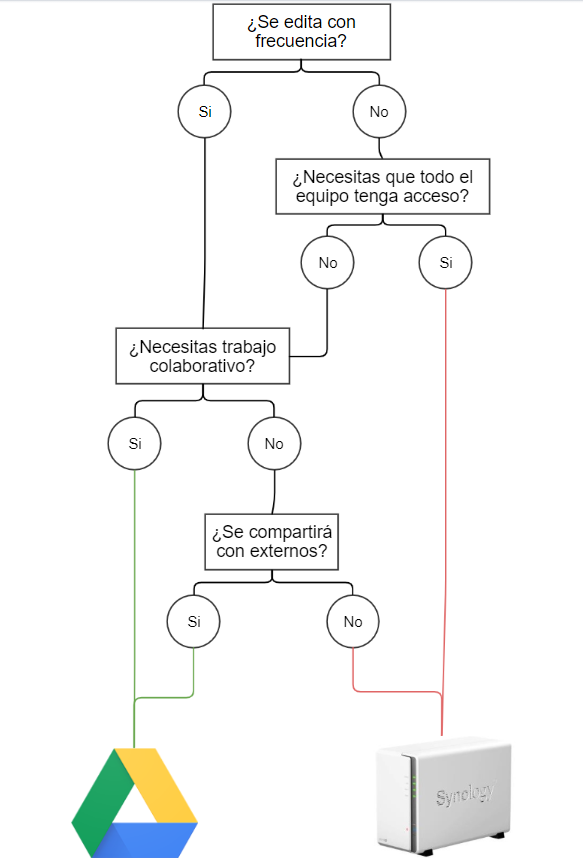
Problema resuelto!
Buenas prácticas: ¿Email o chat?
Estás a punto de enviar un mensaje para actualizar a su compañera de trabajo sobre su último proyecto. ¿Escribes un correo electrónico o le escribes a Hangouts?
Tradicionalmente, los mejores casos para usar el correo electrónico son cuando:
- El contenido es demasiado largo para enviar mensajes.
- El mensaje es información pesada.
- El mensaje requiere formalidad.
- Es la primera vez que contactas a alguien
Los mejores casos para usar el chat son cuando:
- Debe ser rápido y oportuno
- El mensaje es conciso.
- Es un diálogo con múltiples personas
- La discusión debe ser más informal.
Árbol de decisión
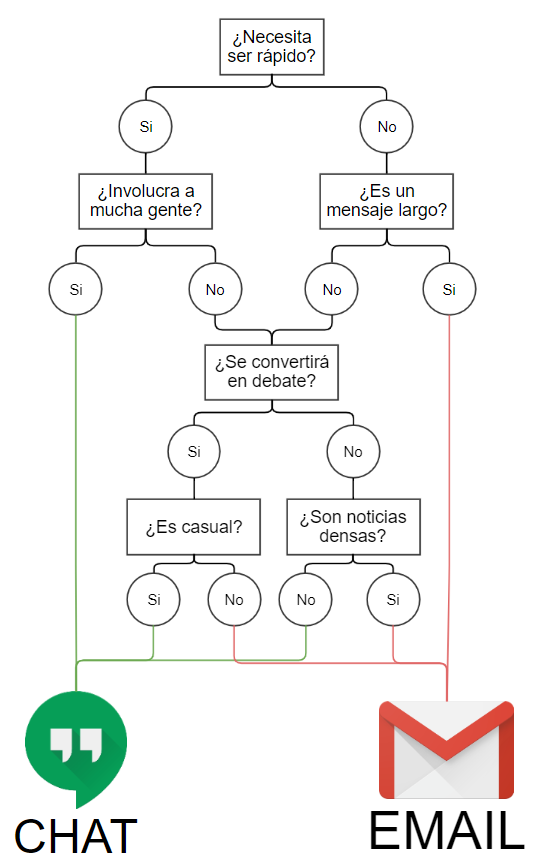
Por qué
Oportunidad
El correo electrónico es asíncrono, lo que significa que un correo electrónico que envía a su compañero de trabajo no es en tiempo real como
lo es la mensajería. Esta es una diferencia clave para el razonamiento detrás del uso de uno versus el otro. La mensajería es instantánea, por lo
que sería más rápido que el correo electrónico cuando se trata de enviar información a alguien.
Según un estudio sobre el uso de mensajes por parte de IBM, la razón principal por la cual las personas eligen usar mensajes en cualquier otro
medio en un momento dado es porque permite una «respuesta rápida» y «respuestas rápidas y cortas».
Longitud
Originalmente, el chat estaba destinado a ser breve, mientras que el correo electrónico podía manejar mensajes más voluminosos y con mucho
contenido. Esto es una ventaja cuando se trata de mensajes porque significa que puedes ser más informal y rápido con lo que tienes que decir.
Pedir a los compañeros de trabajo que almuercen contigo se comunica mejor a través de mensajes, mientras que dar a alguien detalles largos
sobre un informe sería mejor por correo electrónico.
Diálogo
Tanto el correo electrónico como la mensajería se usan para el diálogo, pero el correo electrónico de ida y vuelta es muy diferente a la
mensajería. El chat es mejor si la conversación continuará durante más de unas pocas oraciones. El chat también refleja el cara a cara
más que el correo electrónico, lo que también es una razón para usar uno sobre el otro cuando se trata de largas conversaciones en línea.
Según un estudio de The Radicati Group, «el uso comercial de mensajería instantánea está creciendo a un ritmo mucho más rápido que el uso
de mensajería instantánea por parte de los consumidores». El estudio analiza todo tipo de mensajes, incluidos mensajes instantáneos,
mensajería instantánea pública, mensajería instantánea empresarial y mensajería móvil. El crecimiento de la mensajería muestra que el correo
electrónico no es la única forma de enviar un mensaje en el trabajo.
Problema resuelto!