
Subir imágenes al Container Registry de GCP
No es nada complicado, pero es importante que hay tres maneras diferentes de subir una imágen al repositorio de GCP.
Dockerfile
1. Crea o descarga un fichero Dockerfile
Con tu editor de texto favorito, o bien descargado de Dockerhub, sitúa el fichero Dockerfile en la carpeta que quieras.
2. Compila la imagen con Dockerfile
Cloud Build te permite compilar una imagen de Docker mediante un Dockerfile. No necesitas un archivo de configuración de compilación diferente.
Ejecuta el comando siguiente desde el directorio que contiene quickstart.sh y Dockerfile, en el que [PROJECT_ID] es tu ID del proyecto de GCP:
gcloud builds submit --tag gcr.io/[PROJECT_ID]/[IMAGE_NAME] .Ejemplo:
gcloud builds submit --tag gcr.io/tg-gcp-project/rabbitmq .YAML
- Crea un Dockerfile con la información que necesites.
- En el mismo directorio que contiene Dockerfile, crea un archivo llamado cloudbuild.yaml con los contenidos siguientes. Este archivo es tu archivo de configuración de compilación. A la hora de la compilación, Cloud Build reemplaza $PROJECT_ID con tu ID del proyecto de manera automática.
steps:
name: 'gcr.io/cloud-builders/docker'
args: [ 'build', '-t', 'gcr.io/$PROJECT_ID/rabbitmq2', '.' ]
images: 'gcr.io/$PROJECT_ID/rabbitmq2'3. Comienza la compilación con la ejecución del comando siguiente:1 gcloud builds submit --config cloudbuild.yaml .
Nota
No omitas el «.» al final del comando anterior. Con “.”, se especifica que el código fuente se encuentra en el directorio de trabajo actual al momento de la compilación.
Imagen Local
Etiqueta la imagen local con el nombre del registro mediante el siguiente comando:
docker tag [SOURCE_IMAGE] [HOSTNAME]/[PROJECT-ID]/[IMAGE]Envía la imagen etiquetada a Container Registry con el siguiente comando:
docker push [HOSTNAME]/[PROJECT-ID]/[IMAGE]docker push [HOSTNAME]/[PROJECT-ID]/[IMAGE]:[TAG]
Problema resuelto!
Alertas Útiles en Google Cloud Platform
Intro
Me gustaría empezar esta entrada con un síntoma que he sufrido bastante en las empresas donde he tenido el placer de trabajar:
El Día a Día Me Come (DDMC)
Fransu Rondán
Se podría aplicar en muchos aspectos, tanto personales como profesionales. Pero hoy me gustaría hacer hincapié en esa gran aliada, apenas utilizada en las infraestructuras de sistemas: La monitorización.
Da igual como se llame la herramienta: Stackdriver, Zabbix, Nagios… Es una inversión de tiempo que se recupera a corto plazo. Lo importante es tenerla, configurarla y hacerle caso.
Ventajas
- Detección e identificación temprana de problemas.
- Ejecución de acciones preventivas.
- Alertas y notificación de las incidencias.
- Generación de informes de rendimiento y seguridad.
- Capacidad para optimizar recursos.
¿Qué monitorizar?
En esta entrada no vamos a centrar en los indicadores del rendimiento (KPI) de VM y de contenedores de Kubernetes, en concreto la RAM y CPU, puesto que Google Cloud Platform es una plataforma demasiado flexible para detallarlo todo.
Memoria
Instancias de máquina virtual
| Nombre del recurso | VM Instance |
| Etiqueta del recurso en la consulta | gce_instance |
| Nombre de la métrica: | Memory utilization |
| Descripción de la métrica: | Tamaño en bytes de memoria usada obtenida utilizando el agente de stackdriver. |
| Etiqueta de la métrica en la consulta: | agent.googleapis.com/memory/percent_used |
| Tipos de memoria disponibles para la monitorización: | buffered cached free slab1 used |
| Nombre del recurso | VM Instance |
| Etiqueta del recurso en la consulta | gce_instance |
| Nombre de la métrica: | VM Memory Used |
| Descripción de la métrica: | Memoria actual usada en la VM. Solo disponible para las VM de la familia e2. |
| Etiqueta de la métrica en la consulta: | compute.googleapis.com/instance/memory/balloon/ram_used |
| Tipos de memoria disponibles para la monitorización: | buffered cached free slab1 used |
Kubernetes
| Nombre del recurso | GKE Container |
| Etiqueta del recurso en la consulta | k8s_container |
| Nombre de la métrica: | Memory Usage |
| Descripción de la métrica: | Uso de memoria en bytes |
| Etiqueta de la métrica en la consulta: | kubernetes.io/container/memory/used_bytes |
| Tipos de memoria disponibles para la monitorización: | evitable: Fácilmente reclamada por el kernel non-evitable: No fácilmente reclamada por el kernel |
CPU
INSTANCIAS DE MÁQUINA VIRTUAL
| Nombre del recurso | VM Instance |
| Etiqueta del recurso en la consulta | gce_instance |
| Nombre de la métrica: | CPU utilization |
| Descripción de la métrica: | Porcentaje de CPU usado obtenido utilizando el agente de stackdriver. |
| Etiqueta de la métrica en la consulta: | agent.googleapis.com/cpu/utilization |
| Estados de CPU disponibles para la monitorización: | idle: Cuando no lo está usando ningún programa. interrupt: Señales enviadas por dispositivos externos a la CPU para detener las actividades actuales. nice: Tiempo dedicado a ejecutar procesos con buen valor positivo. softirq: Cuando se ejecuta un controlador de interrupciones o una función diferible. steal: Tiempo que una CPU virtual espera una CPU real mientras el hipervisor está dando servicio a otro procesador. system: CPU utilizada por el sistema user: CPU utilizada por el usuario wait: cantidad de tiempo que una tarea tiene que esperar para acceder a los recursos de la CPU |
Hay muchos tipos de memoria, y todos deberían ser monitorizados. Sin embargo, considero que lo más fácil sería monitorizar que siempre tengamos un porcentaje libre de idle. No sabremos que tipo de memoria exactamente está dando el problema, pero detectaremos que algo está ocurriendo y podremos tomar medidas.
Podríamos configurar alertas, por ejemplo, que detectaran cuando la memoria idle disponible es inferior al 30% durante 1h.
| Nombre del recurso | VM Instance |
| Etiqueta del recurso en la consulta | gce_instance |
| Nombre de la métrica: | CPU utilization |
| Descripción de la métrica: | Utilización fraccionada de la CPU asignada. Los valores son típicamente números entre 0.0 y 1.0. Los gráficos muestran los valores como un porcentaje entre 0% y 100% |
| Etiqueta de la métrica en la consulta: | compute.googleapis.com/instance/cpu/utilization |
| Valores de CPU disponibles para la monitorización: | cpu/utilization |
Kubernetes
Debido a la forma de funcionar y a la lógica de Kubernetes, GCP no nos proporciona para los contenedores un parámetro utilization como pasaba con las máquinas virtuales. En su lugar nos ofrece los siguientes parámetros:
- kubernetes.io/container/cpu/core_usage_time
- kubernetes.io/container/cpu/limit_cores
- kubernetes.io/container/cpu/limit_utilization
- kubernetes.io/container/cpu/request_cores
- kubernetes.io/container/cpu/request_utilization
Sin embargo, si queremos saber el uso de CPU, los clusters de GKE al final son maquinas virtuales en el entorno de GCE. Para evitarnos sustos, siempre es recomendable tener el cluster monitorizado como una máquina más.
Discos / Volumenes
Instancias de máquina virtual
| Nombre del recurso | VM Instance |
| Etiqueta del recurso en la consulta | gce_instance |
| Nombre de la métrica: | Disk usage |
| Descripción de la métrica: | Disco usado en bytes obtenido utilizando el agente de stackdriver. Solo para VM Linux. |
| Etiqueta de la métrica en la consulta: | agent.googleapis.com/disk/bytes_used |
| Tipo de uso: | free reserved used |
| Nombre del recurso | VM Instance |
| Etiqueta del recurso en la consulta | gce_instance |
| Nombre de la métrica: | Disk usage in Bytes |
| Descripción de la métrica: | Disco usado en bytes. |
| Etiqueta de la métrica en la consulta: | compute.googleapis.com/guest/disk/bytes_used |
| Valores de CPU disponibles para la monitorización: | cpu/utilization |
Filtros:
- resource.namespace_name
- resource.container_name
- metric.memory_type:
- Values:
evictable: It is memory that can be easily reclaimed by the kernelnon-evictable. , Is memory that can not be easily reclamied by the kernel.
- Values:
Chuleta – Pipeline para Jenkins
En mi día a día, trabajo bastante con Jenkins. Nada del otro universo, una maquinita local, corriendo jenkins, vinculada con gcloud y cuenta de servicio. Tengo toda la potencia del bash de unix y la versatilidad de Jenkins como CI.
pipeline {
agent any
environment {
STAGE_NAME_BB = ""
SRC_PATH="[local_src_path]" #Ruta donde deberá encontrarse el proyecto GIT que debe ser compilado.
SCRIPTS_PATH="[scripts_path]" #Ruta donde se almacena el script para eliminar las imágenes antiguas
NAMESPACE="[k8_namespace]"
K8_OBJ="[workload_type]/[workload_name]"
CONTAINER="[container_name]"
IMAGE="[src_image]"
}
stages {
stage("Compile Code"){
steps {
notifyBuild("STARTED")
script{
STAGE_NAME_BB = "Compile Code"
}
echo "Building..."
sh "Comandos a ejecutar para la compilación del código"
}
}
stage("Unit Testing"){
steps {
script{
STAGE_NAME_BB = "Unit testing"
}
echo "En este apartado puedes configurar los test para tu código"
}
}
stage("Image Push & Tag into Container Registry"){
steps {
script{
STAGE_NAME_BB = "Image Push & Tag into Container Registry"
}
echo "# Subir la imagen al container registry..."
sh "cd ${SRC_PATH} && mvn jib:build -Djib.to.image=${IMAGE}:${BUILD_NUMBER}"
echo "# Agregar la etiqueta latest a la imagen que acabamos de subir"
sh "cd ${SRC_PATH} && gcloud container images add-tag ${IMAGE}:${BUILD_NUMBER} ${IMAGE}:latest --quiet"
}
}
stage("Deploying Image into its Kubernetes Container"){
steps {
script{
STAGE_NAME_BB = "Deploying Image into its Kubernetes Container"
}
echo "# Connecting to dev cluster"
sh "gcloud container clusters get-credentials [cluster-name] --zone [cluster-zone] --project [project-name]"
echo "# Configurar la nueva imagen como la ultima imagen de la carga de trabajo especificada"
sh "cd ${SRC_PATH} && kubectl set image ${K8_OBJ} ${CONTAINER}=${IMAGE}:${BUILD_NUMBER} --record -n ${NAMESPACE}"
}
}
stage("Delete Container Registry Old Images"){
steps {
script{
STAGE_NAME_BB = "Delete Container Registry Old Images"
}
echo "# Deleting old images"
echo "# Para mas detalles de este script, podéis consultar esta entrada"
sh "cd ${SCRIPTS_PATH} && ./delete_old_images.sh ${IMAGE}"
}
}
}
post {
success {
notifyBuild("SUCCESSFUL")
}
failure {
notifyBuild("FAILED ${STAGE_NAME_BB}")
}
}
}
def notifyBuild(String buildStatus = 'STARTED') {
// build status of null means successful
buildStatus = buildStatus ?: 'SUCCESSFUL'
// Default values
def colorName = 'RED'
def colorCode = '#FF0000'
def subject = "${buildStatus}: Job '${env.JOB_NAME} [${env.BUILD_NUMBER}]'"
def summary = "${subject} (${env.BUILD_URL})"
// Override default values based on build status
if (buildStatus == 'STARTED'){
color = 'YELLOW'
colorCode = '#FFFF00'
summary = "${subject} (${env.BUILD_URL})"
}
else if (buildStatus == 'SUCCESSFUL') {
color = 'GREEN'
colorCode = '#00FF00'
}
}
Problema resuelto!
Buenas prácticas: ¿Almacenaje cloud o NAS?
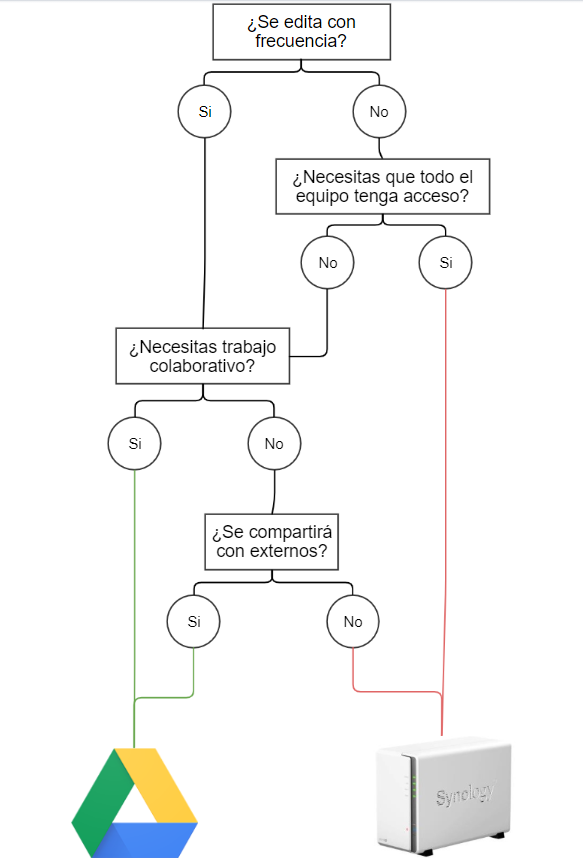
Estás a punto de guardar un documento pero no estás seguro donde debería estar guardado. ¿Lo guardas en el cloud o lo guardas en la NAS?
Tanto Cloud (OneDrive, Google Cloud) como la NAS son dos servicios de almacenamiento de archivos. Ambos son medios son complementarios entre sí dentro del lugar de trabajo, pero hay ciertos casos en los que es mejor usar uno u otro. Depende de la situación.
Tradicionalmente, los mejores casos para usar Cloud son cuando:
- Necesitas compartir un archivo/carpeta con externos a la organización.
- Es un archivo “vivo”. Se edita y modifica con frecuencia.
- Necesitas realizar trabajo colaborativo simultáneo sobre el archivo con otro compañer@.
- Es un archivo que solo lo vas a usar tu.
Los mejores casos para usar la NAS son cuando:
- No necesitas trabajo colaborativo
- Es un archivo “estático”, que sufre pocos o ningún cambio a lo largo del tiempo.
- Tiene que estar en un repositorio común para todos los miembros del equipo.
Problema resuelto!